Your AI isn’t failing because the model is weak. It’s failing because it forgets. Learn why every LLM needs a memory layer, why most companies build it wrong, and how to design memory that actually scales.
Introduction: The RAG Hype vs Reality
he first red flag wasn’t a system alert.
It was a sentence from a frustrated user:
“Why does your AI keep explaining things we already decided?”
The demo had gone perfectly.
The assistant sounded smart. Confident. Helpful.
But in production, something strange happened.
It forgot preferences.
It repeated reasoning.
It contradicted decisions made minutes earlier.
Sometimes it behaved like a brand-new system every single day.
The model wasn’t broken.
The architecture was.
This is the uncomfortable truth most teams discover too late: LLMs don’t remember.
They predict. And without a properly designed LLM memory layer, prediction quickly turns into inconsistency.
Contact us
Start Your Innovation Journey Here
The Illusion of Memory in LLMs
LLMs feel intelligent because they sound continuous. Humans mistake fluency for recall.
In reality:
- The model only sees what fits inside the current context window
- When that window resets, everything disappears
- No decisions persist
- No preferences carry over
- No workflow state survives
Compression is not memory.
Statistical patterns are not recall.
When enterprises try to run real workflows on stateless systems, the failure modes are brutal:
- Multi-step tasks restart halfway
- Agents redo work they already completed
- Answers change depending on retrieval noise
- Users lose trust because nothing feels stable
A stateless engine cannot power a stateful business.
Without an LLM memory layer, intelligence has no continuity.
What “Memory” Actually Means (And Why Vector Databases Aren’t Enough)
Most companies hear “memory” and think: vector database.
They store everything and hope retrieval saves them.
It doesn’t.
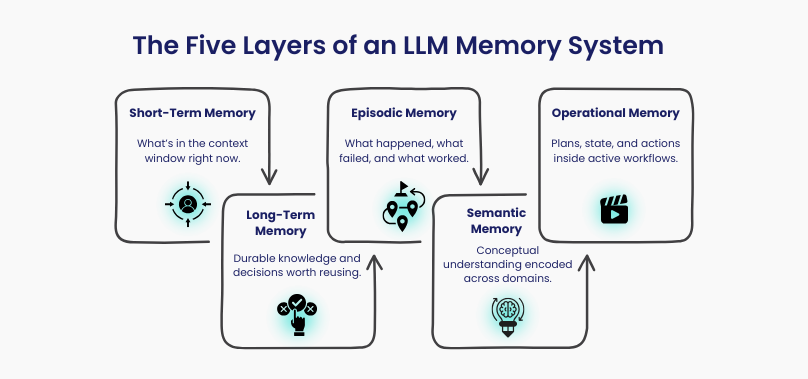
Real AI memory has layers, each with a different role:
- Short-Term Memory
The context window. Fast, powerful, and extremely limited.
- Long-Term Memory
Structured summaries, decisions, and knowledge designed for reuse.
- Episodic Memory
Logs of interactions, failures, and outcomes that allow systems to improve.
- Semantic Memory
Conceptual embeddings and domain understanding.
- Operational Memory
The most neglected layer: what already happened in the workflow, which tools ran, and what remains unfinished.
Memory is not a feature.
It is a system.
Most organizations build one layer and call it done.
Memory is not a feature. It is a system. Most organizations build one layer and call it done.
The failures follow a pattern:
- Everything is stored, nothing is curated
- Raw transcripts replace structured knowledge
- Retrieval injects irrelevant noise
- Agents forget plans mid-execution
- User preferences reset every session
- No governance, no cleanup, no versioning
This creates memory rot.
The more the system “remembers,” the worse it performs.
Bad memory doesn’t make AI less intelligent.
It makes it unpredictable.
The Memory Architecture That Actually Works
A production-grade LLM memory layer looks less like a database and more like infrastructure.
It includes:
- A managed context window with compression and structure
- Long-term memory built from summaries, not logs
- Hybrid retrieval (vector + keyword) with reranking
- Stateful agent memory that tracks plans and actions
- A user modeling layer for preferences and constraints
- Governance across everything: what to store, when to update, when to forget
Memory is a pipeline, not a bucket.
Why Memory Is the Real Foundation of Autonomous AI
Agents without memory behave like talented interns with no notebook.
They:
- Repeat work
- Forget decisions
- Loop endlessly
- Change explanations mid-task
Memory enables:
- Multi-step reasoning
- Tool planning
- Intent carryover
- Personalization
- Error correction
- Learning from failure
Autonomy does not come from bigger models.
It comes from a better LLM memory layer.
Enterprise Memory Design Principles That Actually Hold Up
Teams that succeed follow simple but strict rules:
- Store less, compute more
- Summaries beat transcripts
- Segment memory by purpose
- Treat state as critical infrastructure
- Version everything
- Govern aggressively
If everything is remembered, nothing is useful.
The Quiet Risks of Bad Memory
Bad memory systems don’t crash.
They corrode.
They introduce:
- Memory drift that poisons reasoning
- Retrieval instability that breaks trust
- Compliance risks that go unnoticed
- Cost explosions from unbounded storage
- Inconsistent personalization that frustrates users
These failures are subtle, and that’s why they’re dangerous.
Conclusion: Intelligence Without Memory Is a Party Trick
LLMs without memory impress in demos.
LLMs with memory survive production.
LLMs with a well-engineered LLM memory layer become reliable, adaptive systems.
Most AI products aren’t failing because the models are weak.
They’re failing because they forget.
The next competitive advantage in AI won’t be bigger brains.
It will be better memory.
Contact Us
If your AI systems need consistency, autonomy, and enterprise reliability, we help teams design and implement scalable LLM memory layer architectures that don’t decay in production.
Contact us to build AI systems that remember what matters.
From strategy to delivery, we are here to make sure that your business endeavor succeeds.
Whether you’re launching a new product, scaling your operations, or solving a complex challenge Hoop Konsulting brings the expertise, agility, and commitment to turn your vision into reality. Let’s build something impactful, together.
Free up your time to focus on growing your business with cost effective AI solutions!