Retrieval-Augmented Generation looks powerful in demos but often fails in production. Learn why RAG breaks, common failure modes, and the architecture that makes Retrieval-Augmented Generation reliable at scale.
Introduction: The RAG Hype vs Reality
Most teams first encounter Retrieval-Augmented Generation through a polished demo. A question goes in, relevant documents appear, and the model responds with confident, well-cited answers. It feels like magic. It feels inevitable.
Then production happens.
Suddenly, answers sound correct but are wrong. Retrieval surfaces irrelevant documents. Latency spikes without warning. Updating data breaks previously working queries. Users ask ambiguous questions, and the system collapses under its own confidence.
This is not because RAG is flawed.
It’s because Retrieval-Augmented Generation is fragile when engineered naively.
This article explains why RAG fails so often and the architecture that actually makes Retrieval-Augmented Generation reliable in production.
Contact us
Start Your Innovation Journey Here
Section 1: Why Retrieval-Augmented Generation Breaks Under Real Conditions
- Retrieval Is Probabilistic, Not Deterministic
Unlike traditional databases, Retrieval-Augmented Generation relies on similarity search. Similarity is statistical, not guaranteed.
- The same query can return different documents
- Small embedding shifts change ranking
- “Close enough” retrieval leads to confident hallucinations
When retrieval is wrong, the model doesn’t hesitate it explains the wrong answer beautifully.
- Embeddings Approximate Meaning, They Don’t Understand It
Embedding models do not encode truth. They encode patterns.
This becomes dangerous in regulated or technical domains where:
- Acronyms overlap
- Language is precise
- Context matters more than surface similarity
In Retrieval-Augmented Generation, this leads to hallucinations with citations the most damaging failure mode.
- Chunking Quietly Determines Success or Failure
Chunking looks like a configuration detail. It isn’t.
- Small chunks → loss of context → noisy retrieval
- Large chunks → irrelevant text → confused reasoning
In real systems, poor chunking is responsible for a large percentage of Retrieval-Augmented Generation failures.
- Indexes Degrade Over Time
Data changes. Policies evolve. Documents get updated.
Indexes don’t unless you force them to.
Without lifecycle management, Retrieval-Augmented Generation systems confidently serve outdated knowledge while appearing fully functional.
Section 2: Engineering Decisions That Break Most RAG Systems
Most RAG failures are engineering failures, not AI failures.
- Precision vs Recall Is Rarely Tuned
The default “top-k = 5” retrieval strategy fails more often than it succeeds.
- Too few results → missing critical context
- Too many results → noise overwhelms the model
Effective Retrieval-Augmented Generation requires query-aware, dynamic retrieval, not static defaults.
- Latency Erodes Trust
Vector search, reranking, and generation stack latency quickly.
- 1 second feels fast
- 3 seconds feels slow
- 6 seconds feels broken
Users don’t blame architecture. They stop trusting the system.
- No Retrieval Evaluation = No Reliability
Teams evaluate answers, not retrieval quality.
Without measuring:
- Retrieval precision
- Coverage
- Relevance
You cannot debug or improve Retrieval-Augmented Generation in a meaningful way.
- RAG Without Reranking Is Incomplete
Cross-encoder rerankers dramatically improve relevance.
They:
- Filter irrelevant chunks
- Stabilize answers
- Reduce hallucinations
Skipping reranking to “save cost” usually increases downstream failures.
Section 3: Predictable Production Failure Patterns
Most Retrieval-Augmented Generation systems fail in the same ways:
- Sounds right, but is wrong due to irrelevant retrieval
- Worked yesterday, broken today because of index or embedding drift
- Perfect prototype, chaotic production because real users don’t ask clean questions
- Too slow to use as traffic increases
These failures are not random. They are architectural.
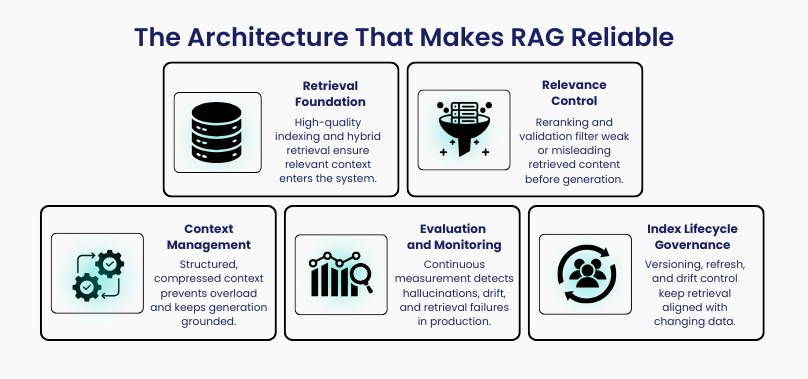
Section 4: The Architecture That Makes Retrieval-Augmented Generation Reliable
Reliable Retrieval-Augmented Generation systems use layered defense, not single-step pipelines.
A production-grade RAG architecture includes:
- Multi-stage retrieval
- Fast vector search for recall
- Sparse/BM25 search for exact terms
- Hybrid fusion for robustness
- Cross-encoder reranking for precision
- Retrieval validation
- Reject low-relevance context
- Trigger clarification instead of hallucination
- Structured context injection
- Separate facts, evidence, and instructions
- Avoid raw context dumping
- Context compression
- Summarize documents before injection
- Reduce noise and token waste
- Continuous evaluation
- Monitor retrieval accuracy
- Track hallucination rate and latency
Section 5: When Retrieval-Augmented Generation Works and When It Doesn’t
- RAG works best for:
- Knowledge bases
- Policy and compliance documents
- Product manuals
- Internal enterprise data
- RAG performs poorly for:
- Creative tasks
- Subjective reasoning
- Ambiguous or underspecified queries
- Tasks requiring deep inference
Conclusion: RAG Isn’t Broken Our Implementations Are
Retrieval-Augmented Generation is not plug-and-play.
It fails when treated as a shortcut instead of an engineering discipline.
It succeeds when retrieval is designed, evaluated, validated, and maintained with care.
RAG doesn’t work as advertised.
It works as engineered.
And that difference separates impressive demos from production systems that people actually trust.
Contact Us
If you’re struggling with unreliable Retrieval-Augmented Generation systems or planning to build one that works in the real world our team specializes in production-grade RAG architecture, evaluation frameworks, and enterprise deployment.
Contact us today to design a Retrieval-Augmented Generation system that scales beyond the demo and performs where it matters most: in production.
From strategy to delivery, we are here to make sure that your business endeavor succeeds.
Whether you’re launching a new product, scaling your operations, or solving a complex challenge Hoop Konsulting brings the expertise, agility, and commitment to turn your vision into reality. Let’s build something impactful, together.
Free up your time to focus on growing your business with cost effective AI solutions!